Les machines apprenantes et la (re)production de la société : les enjeux communicationnels de la socialisation algorithmique
Résumé
Comment les technologies d’intelligence artificielle, en automatisant la communication organisationnelle, peuvent-elles contribuer à la (re)production de la société ? Afin de traiter cette question, nous commencerons par exposer ce que nous entendons par socialisation algorithmique. Nous montrerons ensuite que, d’un point de vue théorique, les technologies d’apprentissage artificiel ont pour but d’automatiser les processus de communication au sein des organisations selon des mécanismes de socialisation algorithmique qui favorisent la reproduction de la société. Puis nous soutiendrons que, d’un point de vue empirique, ces machines apprenantes recouvrent un important travail de cadrage de leurs activités inférentielles. Nous verrons de cette façon que l’automatisation de la communication qu’autorisent ces technologies renvoie in fine à des formes de socialisation algorithmique qui contribuent plus à la production qu’à la reproduction de la société.
Mots clés
Socialisation algorithmique, production et reproduction sociale, intelligence et apprentissage artificiels, mégadonnées.
In English
Title
The learning machines and the (re)production of the society: the communicational stakes of algorithmic socialization
Abstract
How can artificial intelligence technologies, by automating organizational communication, contribute to society’s (re)production? In order to address this question, we will start by explaining what we mean by algorithmic socialization. We will then show that, from a theoretical point of view, artificial learning technologies aim to automate communication processes within organizations according to algorithmic socialization mechanisms that promote the reproduction of society. Then we will argue that, from an empirical point of view, these learning machines cover an important work of framing their inferential activities. We will see in this way that the automation of communication that these technologies allow ultimately refers to forms of algorithmic socialization that contribute more to the production than to the reproduction of society.
Keywords
Algorithmic socialization, social production and reproduction, artificial intelligence and learning, big data.
En Español
Título
Máquinas de aprendizaje y (re)producción en la sociedad: los retos de comunicación de la socialización algorítmica
Resumen
¿Cómo pueden las tecnologías de inteligencia artificial, al automatizar la comunicación organizativa, contribuir a la (re)producción de la sociedad? Para responder a esta pregunta, comenzaremos explicando lo que entendemos por socialización algorítmica. A continuación mostraremos que, desde un punto de vista teórico, las tecnologías artificiales de aprendizaje apuntan a automatizar los procesos de comunicación dentro de las organizaciones según mecanismos algorítmicos de socialización que promueven la reproducción de la sociedad. Entonces argumentaremos que, desde un punto de vista empírico, estas máquinas de aprendizaje cubren un trabajo importante de enmarcar sus actividades inferenciales. Veremos así que la automatización de la comunicación que permiten estas tecnologías se refiere en última instancia a formas de socialización algorítmica que contribuyen más a la producción que a la reproducción de la sociedad.
Palabras clave
Socialización algorítmica, producción y reproducción social, inteligencia y aprendizaje artificiales, mega datos.
Pour citer cet article, utiliser la référence suivante :
Vayre Jean-Sébastien, « Les machines apprenantes et la (re)production de la société : les enjeux communicationnels de la socialisation algorithmique« , Les Enjeux de l’Information et de la Communication, n°19/2, 2018, p.93 à 111, consulté le , [en ligne] URL : https://lesenjeux.univ-grenoble-alpes.fr/2018/dossier/07-les-machines-apprenantes-et-la-reproduction-de-la-societe-les-enjeux-communicationnels-de-la-socialisation-algorithmique/
Introduction
Comme le montre les travaux de Pierre Musso (2017), les sociétés occidentales contemporaines sont caractérisées par une triple dynamique : la révolution managériale, le développement de la cybernétique et celui des Technologies de l’Information et de la Communication (TIC). Plusieurs auteurs ont ainsi mis en avant que les évolutions récemment élaborées dans le domaine de l’apprentissage artificiel(1) (i.e. machine learning) sont au cœur du mouvement de numérisation que connaissent actuellement les organisations (Boullier, 2016 ; Cardon, 2015 ; Ganascia, 2017). En permettant aux machines d’apprendre à partir de grandes masses de données, ces évolutions doivent autoriser l’automatisation de la communication d’une part toujours plus importante des informations que les hommes et les machines s’échangent pour coordonner leurs actions, et faire exister leurs organisations. L’objectif est alors de favoriser la modularisation des procédés de production et de distribution des biens de consommation (Maistre, 2016 ; Laumond, 2016) de manière à préparer l’avènement d’une société de services véritablement personnalisés (Kohler & Weisz, 2016).
Les algorithmes d’apprentissage que les acteurs économiques conçoivent et implémentent au sein de leurs entreprises ont de cette façon pour but d’accroître l’« agentivité » (i.e., agency ; Pickering, 1995) des systèmes d’information qui les composent. Ils doivent permettre aux machines d’inférer des connaissances sur le monde de façon à ce qu’elles puissent communiquer aux entités sociales et techniques qui forment l’organisation les informations lui permettant de s’adapter aux évolutions de son environnement. Aussi, à l’ère de ce que les professionnels appellent la société 4.0, la question du rôle des machines est centrale : les enjeux communicationnels qui sont associés à l’accroissement progressif de l’autonomie cognitive que leur confèrent les humains sont importants. C’est pourquoi nous proposons dans cet article de traiter le questionnement suivant : en automatisant la communication organisationnelle, comment les technologies d’intelligence artificielle qui sont aujourd’hui développées peuvent-elles contribuer à la (re)production de la société ?
Pour traiter cette problématique, nous commencerons par exposer les cadres théorique et méthodologique que nous avons mobilisés pour effectuer notre enquête. Ceci nous amènera à présenter la notion de socialisation algorithmique ainsi que les limites de notre étude qui porte avant tout sur le cas des technologies d’apprentissage artificiel appliquées à la gestion de la relation client. Nous exposerons ensuite nos résultats en deux grandes sections. Dans la première, nous verrons que, sur le plan théorique, les technologies d’apprentissage artificiel ont pour but d’automatiser des processus de communication selon des mécanismes de socialisation algorithmique qui favorisent la reproduction de la société. Dans la seconde section, nous soutiendrons que, sur le plan empirique, les machines apprenantes auxquelles nous nous sommes intéressé recouvrent un important travail de cadrage de leurs activités inférentielles. Nous verrons de cette manière que, non plus d’un point de vue abstrait mais concret, l’automatisation de la communication qu’autorisent ces technologies renvoie in fine à des formes de socialisation algorithmique qui contribuent plus à la production qu’à la reproduction de la société.
Cadres théorique et méthodologique
Dans cette première section, nous présentons les cadres théorique et méthodologique que nous avons déployés pour réaliser notre enquête. Cette partie nous permettra donc d’exposer notre positionnement disciplinaire qui se trouve au croisement des sciences de l’information, de la communication, de la sociologie des sciences et de celle des techniques. En référence aux travaux de Bernard Miège (2007), l’étude que nous présentons dans cet article relève des sciences de l’information et de la communication puisqu’elle consiste à examiner : « des processus d’information et de communication relevant d’actions contextualisées, finalisées, prenant appui sur des techniques, sur des dispositifs, et participant des médiations sociales et culturelles »(2) (Miège, 2007, p. 199-200). Comme nous l’avons souligné en introduction, les technologies d’apprentissage artificiel ont pour fonction d’automatiser une part toujours plus grande des processus de communication qui se déroulent entre l’immense diversité des acteurs sociaux qui font usages des TIC. Aussi, nos travaux relèvent des sociologies des sciences et des techniques dans le sens où ils portent un intérêt particulier aux rôles que jouent ces technologies d’apprentissage artificiel au sein des sociétés occidentales contemporaines.
Afin d’exposer les cadres théorique et méthodologique que nous avons élaborés pour effectuer notre étude, nous proposons de commencer par présenter le concept d’agentivité et la manière dont il peut être compris dans le cas des objets techniques. Nous soulignerons de cette façon l’intérêt de la notion de socialisation algorithmique pour saisir les enjeux communicationnels associés au développement des machines apprenantes. Nous exposerons ensuite les matériaux sur lesquels s’appuie notre enquête. Et nous pointerons les limites de notre étude qui porte essentiellement sur le cas des technologies d’apprentissage artificiel appliquées à la gestion de la relation client.
Cadre théorique
La notion d’agentivité a beaucoup été utilisée dans le domaine de la psychologie sociale afin de pointer les capacités d’action dont les humains disposent pour organiser leur environnement (Jézégou, 2014). Ce concept a plus exactement été forgé en opposition aux travaux des sociologues les plus déterministes qui pensent qu’au cours de leurs socialisations, les individus incorporent les normes, les règles et les valeurs qui composent la société. Par exemple, à la différence du sociologue Pierre Bourdieu (1970), le psychologue Albert Bandura (1986) ne considère pas les humains comme des agents se conformant passivement aux rôles que leur impose le collectif. Il les appréhende plutôt comme des acteurs qui savent anticiper et ajuster leurs actions en fonction des croyances qu’ils ont de leurs compétences, de celles des autrui et des objectifs qui orientent leurs activités. Dans le sens des travaux de Georges H. Mead (2015), la notion d’agentivité permet par là même d’insister sur les capacités d’autodirection dont disposent les humains pour construire leur socialisation.
Autrement dit, le fait de mobiliser ou non le concept d’agentivité constitue un bon indicateur de la façon dont les chercheurs en sciences humaines et sociales se représentent la société(Giddens, 1986). Avec cette notion, l’ordre social n’est plus structuré par les forces mystérieuses d’un être surplombant qui s’appellerait « société ». Il est la résultante des interactions qu’entretiennent les humains : c’est par le biais de l’agentivité que les individus sont capables de produire et de communiquer les informations leur permettant de préserver ou de transformer les normes, les valeurs et les règles de la société de manière à construire son historicité. C’est donc à travers cette même agentivité que les humains peuvent contribuer à la reproduction de la société – c’est-à-dire maintenir sa stabilité dans la durée (cf. la notion de statique sociale) – mais aussi à sa production – c’est-à-dire orienter son évolution dans le temps (cf. la notion de dynamique sociale).
Dans la continuité des travaux susmentionnés, de nombreux auteurs se sont appropriés la notion d’agentivité pour désigner, non plus les capacités d’action des humains sur le monde, mais celles des objets techniques (Bouillon, 2015 ; Callon, 1998 ; Cooren & Fairhurst, 2009 ; Denis & Pontille, 2010 ; Latour, 1994). Car ceux-ci sont porteurs de scénarii d’usage qui sont élaborés à travers diverses activités de « description » des mondes à l’intérieur desquels ils doivent être implémentés et d’« inscription » de ces mondes dans la conception même de ces objets (Akrich, 1987 ; 1989). Pour Madeleine Akrich (1987 ; 1989), les objets techniques peuvent de ce fait être compris comme des signes porteurs de sens dans la mesure où ils communiquent plus ou moins explicitement les visions de ceux qui les conçoivent : les objets techniques recouvrent des schèmes cognitifs qui, une fois cristallisés dans leurs conceptions même, renvoient à des « prescriptions » d’usage qui doivent être correctement interprétées par les utilisateurs (Akrich, 2004). Et c’est précisément en ce sens que ces objets sont dotés d’une agentivité : à l’instar des humains, ils participent à la structuration de la société, c’est-à-dire à sa (re)production.
À l’heure actuelle, un tel élargissement du concept d’agentivité est pertinent pour au moins une raison. Les applications socioéconomiques des technologies d’apprentissage artificiel ont pour finalité de conférer une certaine autonomie cognitive aux machines de façon à ce qu’elles puissent communiquer aux entités humaines et matérielles qui composent l’organisation des informations leur permettant d’adapter leurs comportements en fonction : d’une part, des évolutions de leurs environnements et, d’autre part, des objectifs que leurs concepteurs leur prêtent (Vayre, 2016). Or, si l’on accepte le fait qu’il puisse exister une certaine symétrie entre les capacités d’action des hommes et des techniques, il apparaît que le problème que pose l’apprentissage autonome des machines fait écho à celui que pose la socialisation des humains, à tout le moins selon la conception que certains d’entre d’eux s’en font. Rappelons par exemple que, dans la théorie de l’action de Talcott Parsons (2005), ce problème peut être formulé comme suit : comment une organisation peut-elle faire en sorte que les individus qui la composent s’adaptent à son fonctionnement (Adaptation) et suivent ses objectifs (Goal-attainment) de façon à garantir leurs intégrations au sein du groupe (Integration) et, par voie de conséquence, la stabilité du collectif (Latency) ? C’est donc ici que se trouve l’intérêt du concept de socialisation algorithmique : désigner la principale fonction sociotechnique des technologies d’apprentissage artificiel. Car c’est par le biais de cette socialisation d’un type particulier que les humains doivent conférer aux machines l’autonomie cognitive leur permettant de communiquer aux entités sociotechniques qui forment l’organisation les informations autorisant son adaptation à l’environnement que représentent les données qui les nourrissent (i.e., les big data). Et cela, sans pour autant limiter la capacité de contrôle des concepteurs de ces technologies, c’est-à-dire la possibilité, pour ces derniers, d’encadrer et d’orienter les apprentissages qu’elles réalisent.
Partant, en référence aux travaux de Yves Jeanneret (2008) sur la trivialité et par le biais de la notion de socialisation algorithmique, nous souhaitons montrer que les machines apprenantes participent à faire exister les dimensions logistique, sociale et poétique des processus de communication organisationnelle. Afin de permettre l’automatisation de ces processus, ces machines organisent la combinaison et la circulation des traces numériques que recouvrent les big data (cf. la dimension logistique) en fonction des jeux de pouvoir qui associent leurs concepteurs, leurs implémenteurs et leurs utilisateurs (cf. la dimension sociale). Par conséquent et contrairement à ce que certains spécialistes proclament, les informations que ces technologies produisent et communiquent ne sont pas de strictes reproductions des régularités comportementales que les big data doivent permettre d’identifier : les machines apprenantes n’atteignent pas le réel de manière immanente. Les informations qu’elles fabriquent et transmettent au sein des organisations doivent plutôt être comprises comme des créations dans la mesure où elles participent in fine à la transformation des entités cognitives qui forment la culture d’une communauté (cf. la dimension poétique). C’est donc en ce sens que nous proposons, dans cet article, de tester l’hypothèse exploratoire (He) qui suit :
Hypothèse exploratoire (He)De façon analogue aux humains, les technologies d’apprentissage artificiel que ceux-ci implémentent au sein de leurs organisations recouvrent des mécanismes de socialisation qui, au sens stricte du terme, produisent la société plus qu’ils ne la reproduisent.
Cadre méthodologique
Pour mettre à l’épreuve cette hypothèse, nous nous appuierons sur différents matériaux recueillis au cours d’une enquête qui s’est déroulée du mois de septembre 2012 au mois de septembre 2015.
Le premier matériau est constitué d’entretiens et d’observations que nous avons effectués de 2013 à 2015 auprès de cinq entreprises développant des technologies d’intelligence et d’apprentissage artificiels appliquées, pour la plupart d’entre elles, au secteur de la gestion de la relation client (cf. tableau 1). Ces entretiens et ces observations avaient pour finalité de nous permettre de mieux comprendre la conception, le fonctionnement et l’implémentation de ces technologies au sein des organisations commerciales. Ils ont été conduits durant cinq projets de collaboration dont deux ont donné lieu à des partenariats de 18 mois chacun.

Tableau 1 : Présentation des sociétés enquêtées
Le troisième matériau d’enquête est composé d’entretiens qui ont été réalisés avec treize professionnels des données (i.e., data scientists) et qui ont été conduits sur le thème des activités de conception des technologies d’apprentissage artificiel. Le tableau 2 expose les statuts et les formations de l’ensemble de ces professionnels qui, lorsqu’ils ne sont pas spécialisés dans le domaine de la gestion de la relation client ont, au cours de leur carrière, plusieurs fois eu l’occasion de travailler dans ce secteur d’activité.
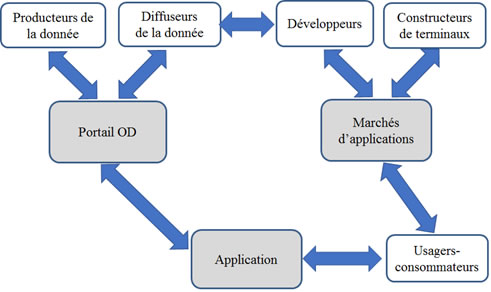
Tableau 2 : Présentation des statuts et des formations des professionnels interviewés
La socialisation algorithmique et la reproduction de la société
Comme nous l’avons annoncé en introduction, cette deuxième section a pour objet de soutenir l’hypothèse selon laquelle, sur le plan purement théorique, les technologies d’apprentissage artificiel appliquées à la gestion de la relation client automatisent des processus de communication organisationnelle selon des mécanismes de socialisation algorithmique qui favorisent la reproduction de la société. Nous nous appuierons pour cela sur l’exemple des réseaux de neurones artificiels qui connaissent un grand succès auprès des acteurs économiques engagés dans le développement du numérique. Rappelons toutefois que, dans la troisième section, nous discuterons cette première hypothèse en soutenant cette fois-ci que, sur le plan empirique, les technologies d’apprentissage artificiel que nous avons étudiées encouragent, au final, la production de la société.
L’exemple des réseaux de neurones artificiels…
Du point de vue de notre problématique, les réseaux de neurones artificiels forment un cas d’étude intéressant pour au moins deux raisons. La première est qu’ils sont construits selon le modèle du perceptron qui est une des plus anciennes technologies d’apprentissage artificiel (McCulloch & Pitts, 1943 ; Rosenblatt, 1958). La deuxième raison est que, comme le montre leur grand succès auprès de Google, Amazon, ou encore, Facebook, ces technologies sont aujourd’hui très appréciées par les professionnels qui sont engagés dans la numérisation des organisations et des marchés. Une des principales causes de cet engouement est qu’avec l’augmentation des puissances de calcul des ordinateurs au cours de ces dernières années, les réseaux de neurones peuvent actuellement être implémentés au sein de petits systèmes informatiques (e.g. un téléphone) de façon à permettre leur adaptation automatique à leur environnement d’usage(3). Cette adaptation est alors permise par un procédé d’apprentissage extrêmement simple qui est plus connu sous le nom de règle de Hebb et qui veut qu’un peu à la manière des neurones biologiques, plus les unités de calcul d’un perceptron s’activent en même temps et plus elles sont liées les unes aux autres (Hebb, 1949). À partir de la formule exposée dans la partie droite de la figure 1, le réseau de neurones artificiels représenté dans la partie gauche pourrait ainsi apprendre à distinguer, par le biais de la sortie y, si l’image représentée par les pixels x1, xi, …, xn forme ou non un carré.
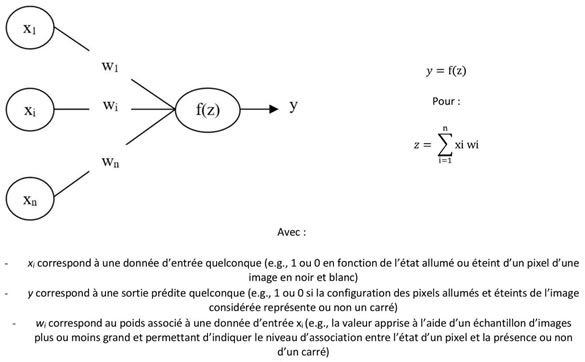
Figure 1 : Réseau de neurones artificiels
Notons alors que cet apprentissage pourrait être effectué au fil de l’eau (cf. Cornuéjols & Miclet, 2010). Par exemple, la technologie d’intelligence artificielle élaborée par la société S_3 s’apparente à un réseau de neurones profond qui est capable d’apprendre les préférences des consommateurs à partir :
- des données d’entrée xi que sont les attributs des produits que composent leurs fiches de présentation et les traces d’usage que forment les données permettant de renseigner la machine sur les comportements des consommateurs ;
- des données de sortie yi que sont les indices de préférence que composent les notations que ces mêmes consommateurs confèrent à ces biens, l’attention qu’ils leur accordent en termes de durée de consultation et l’intérêt qu’ils leur portent en les plaçant ou non dans leurs paniers.
En référence aux travaux de Dominique Cardon et d’Antonio Casilli (2015), la large diffusion des technologies d’apprentissage artificiel dans le domaine de la relation client participe ainsi à redéfinir les frontières entre travail et consommation. Il ne faut en effet jamais oublier que c’est par le biais des indices de préférence produits par les consommateurs, que les machines peuvent effectuer les apprentissages leur permettant de communiquer à ces mêmes clients des informations qui doivent leur apparaître comme pertinentes, et cela, de façon à produire de la plus-value économique pour les marchands. À l’instar des dispositifs de gestion étudiés par Marie-Anne Dujarier (2008) ou par Guillaume Tiffon (2013), le système d’intelligence artificielle élaboré par la société S_3 est un cas caractéristique : selon un processus de communication automatique similaire à celui que nous venons d’exposer, son architecture cognitive est conçue pour « mettre au travail » les consommateurs en économicisant une partie de leurs activités de recherche d’information sur les sites de vente-à-distance. D’après nous, ce point mérite d’être souligné, mais aussi d’être mieux considéré. Il nous rappelle en effet que toute technologie d’apprentissage artificiel, pour fonctionner, nécessite beaucoup de travail humain pour organiser l’environnement que forment les bases de données qui les nourrissent ; même si ce travail est parfois imperceptible compte tenu de son caractère automatique.
… et la reproduction des biais de représentation
Comme l’indique la citation 1 et le verbatim 1 exposés dans la figure 2, les technologies d’apprentissage artificiel que sont les réseaux de neurones artificiels comporteraient deux grands avantages par rapport aux technologies d’intelligence artificielle plus traditionnelles que sont, par exemple, les systèmes experts. Premièrement, à la différence de XCON qui constitue, rappelons-le, un des plus anciens systèmes experts (Crevier, 1997 ; Forgy, 1981), les réseaux de neurones artificiels n’ont pas besoin que leurs concepteurs définissent les règles d’inférence leur permettant de décider, par exemple, des configurations d’ordinateurs dont ont besoin tel et tel groupes de clients. À condition de disposer d’une quantité de données suffisante, ces technologies sont capables d’apprendre ces règles par elles-mêmes. Autrement dit, elles sont capables de découvrir et de coder seules les connaissances dont elles ont besoin pour réaliser leur travail inférentiel, qui pourrait donc consister, par exemple, à apparier des configurations d’ordinateurs et des clients. Comme le montre le cas de XCON (cf. citation 1), cette autonomie cognitive est importante pour les acteurs socioéconomiques dans la mesure où la production de biens et de services personnalisés implique une tolérance de la complexité qui manquait cruellement aux systèmes experts.

Figure 2 : Extraits de matériau d’enquête
Le deuxième avantage est dans la continuité du premier. Il renvoie à l’idée que les technologies d’apprentissage artificiel seraient en capacité d’apprendre des connaissances immanentes au monde, c’est-à-dire qui, à la différence des humains (cf. Tversky & Kahneman, 1974), ne feraient l’objet d’aucun biais de représentation (cf. verbatim 1). Nous savons aujourd’hui que cette idée relève plus de mythe que de la réalité ; et cela, pour des raisons qui, en référence aux théories de la socialisation que propose la sociologie traditionnelle (et plus particulièrement celle de Pierre Bourdieu ; 1994), sont purement logiques. Car les réseaux de neurones artificiels sont conçus selon un modèle d’apprentissage connexionniste qui, sur le plan théorique, correspond à cette modélisation. À l’instar de la philosophie de l’esprit de John R. Searle (2004), il existe, par exemple chez Pierre Bourdieu (1994), l’idée que les institutions sociales sont incorporées, par le biais de la socialisation et sous la forme de structures mentales, dans les cerveaux des humains. Selon Jean-Pierre Changeux (2006), cette idée peut faire l’objet d’une explication d’ordre neurologique : c’est ce qu’il appelle la théorie des « bases neuronales de l’habitus ». Pour cet auteur, la socialisation aurait alors une forme matérielle dans la mesure où elle se manifesterait concrètement par à une grande diversité de configurations d’activation et d’inhibition de neurones biologiques. Or, si la théorie des bases neuronales de l’habitus est discutable(4), il n’en reste pas moins que les réseaux de neurones artificiels appliqués à la résolution de problématiques humaines, comme par exemple celles que pose la gestion de la relation client, la réalisent avec exactitude, à tout le moins d’un point de vue formel.
Attention : ne nous méprenons pas. Nos propos ne consistent ni à anthropomorphiser les machines intelligentes(5), ni à laisser penser que Pierre Bourdieu (1994) aurait œuvré à leur développement (ou encore pour celui des philosophies de l’esprit qui en sont sous-jacentes). Il s’agit plus simplement de souligner la proximité qui existe entre le modèle connexionniste de l’apprentissage qu’encapsulent les réseaux de neurones et le modèle de socialisation que propose Pierre Bourdieu (1994) pour comprendre les mécanismes de reproduction social. Et si nous insistons sur cette proximité, c’est parce qu’elle permet de saisir une des plus graves problématiques éthiques associées au développement des technologies d’apprentissage artificiel au sein des organisations. La congruence qui existe entre le modèle connexionniste de l’apprentissage et le modèle de socialisation que propose Pierre Bourdieu (1994) est importante dans le sens où elle permet de comprendre, selon une perspective qui n’est pas d’ordre strictement technologique mais aussi sociologique, comment les systèmes d’apprentissage artificiel peuvent participer à la diffusion, par exemple, de stéréotypes sexistes ou racistes (cf. Caliskan, Bryson, & Narayanan, 2017) : les réseaux de neurone artificiels sont conçus d’une telle manière qu’ils incorporent au sein de leur architecture cognitive les biais de représentation que véhiculent les couples de données (xi, yi) qui les nourrissent et qui, avec l’avènement des big data, représentent des pans toujours plus grands de la société.
Aussi, bien que les réseaux de neurones ne soient pas les seuls systèmes d’apprentissage artificiel mobilisés par les acteurs socioéconomiques, un grand nombre de ces technologies recouvre, sur le plan purement formel, des mécanismes de production de connaissance dont les implications sociocognitives sont semblables. Le fonctionnement théorique des réseaux de neurones permet par là même de mieux comprendre comment, en autorisant l’automatisation de la communication organisationnelle, les formes de socialisation algorithmique que les technologies d’apprentissage artificiel autorisent peuvent contribuer à la reproduction de la société.
La socialisation algorithmique et la production de la société
Le fonctionnement des technologies d’apprentissage artificiel ne peut toutefois pas être compris par le seul biais de sa dimension théorique. Il renvoie également à une dimension empirique dans la mesure où ces technologies ont pour vocation d’être implémentées, à travers diverses applications, au sein de systèmes sociotechniques concrets. Cette dimension empirique est importante pour bien saisir les formes de socialisation algorithmique que permettent les technologies d’apprentissage artificiel.
Ainsi, l’enquête que nous avons menée sur les activités de conception de ces systèmes montre qu’elles constituent un processus de découverte d’un nouveau marché entre ceux qui les conçoivent et ceux qui les implémentent au sein de leurs organisations. Comme le montrent Sylvain Parasie et Éric Dagiral (2017), ce processus consiste alors, pour le concepteur, à aider l’implémenteur à découvrir et formaliser les connaissances dites métier qui sont nécessaires à la structuration du problème d’apprentissage que la machine doit résoudre. Ce travail d’exploration et de formalisation est opéré durant la conception de trois cadres sociocognitifs qui sont : l’environnement d’apprentissage, l’environnement de traitement et l’environnement politique. Comme nous l’avons souligné plus haut, l’objectif de cette section est de montrer comment, à travers la conception de ces trois cadres, les humains prêtent aux machines apprenantes divers opérateurs de traduction leur permettant de « re-présenter » le monde (Latour, 1996) et d’automatiser la communication selon un angle de vue qui apparaît pertinent aux premiers. Nous soutiendrons de ce fait que c’est par le biais de ces trois cadres que les machines apprenantes participent à la création des entités cognitives qui forment la culture d’une société et, partant, encouragent plutôt sa production que sa reproduction.
La conception de l’environnement d’apprentissage
L’environnement d’apprentissage compose l’assemblage sociotechnique qui autorise la production et le recueil organisés de l’ensemble des données auxquelles la machine peut accéder. En référence aux travaux de Yves Jeanneret (2011 ; 2014), de Béatrice Galinon-Mélénec (2011) et à ceux de Jérôme Denis et Samuel Goëta (2017), cet assemblage est constitué de nombreuses couches sémio et socio-matérielles. Il forme un large dispositif de mise en trace des interactions que les hommes entretiennent avec les technologies numériques et qui s’étend jusqu’aux algorithmes de structuration des bases de données auxquelles les machines apprenantes sont connectées.
Comme le montrent les verbatims de la figure 3, la compréhension de cet assemblage par le concepteur est aussi difficile que fondamentale. Cette difficulté est notamment due au fait que : d’une part, les data des organisations constituent souvent un patchwork de données qui sont produites selon des finalités propres et qui peuvent être éloignées des buts associés aux développements des technologies d’apprentissage artificiel ; et, d’autre part, les personnes qui connaissent l’histoire de ces données sont souvent peu nombreuses et difficiles à identifier (cf. verbatim 2). Pour autant, comme l’indique le verbatim 3, la compréhension de cette histoire est cruciale parce qu’elle permet de mieux saisir les réalités que représentent les données, et, par voie de conséquence, les environnements à partir desquels les machines vont pouvoir effectuer leurs apprentissages. C’est d’ailleurs cette importance et cette complexité qui expliquent pourquoi certains des professionnels que nous avons interrogés préfèrent eux-mêmes poser les « sondes » qui autorisent la production et le recueil automatique des big data.

Figure 3 : Extraits de matériau d’enquête
Les entretiens et les observations que nous avons effectués indiquent alors qu’une bonne partie des activités de conception des technologies d’apprentissage artificiel consiste à trouver et à développer le « bon » système de structuration automatique des données. Pour réaliser cette tâche, les concepteurs passent généralement un certain temps à visualiser les données, à échanger avec les experts métiers sur ce qu’ils peuvent comprendre de ces visualisations et à élaborer les techniques de traitement automatique qui permettront de nettoyer les données, de remplir les valeurs manquantes, de recoder les variables et de les combiner entre elles. Dans leur ensemble, ces activités composent ce que les professionnelles nomment le « feature engeneering » (i.e., l’ingénierie des variables) et ont pour finalité d’organiser l’environnement d’apprentissage de l’algorithme en fonction de la façon dont son concepteur et son implémenteur comprennent la réalité que représentent les données ainsi que le rôle qu’ils souhaitent que la machine remplisse au sein de l’organisation. Pour l’ensemble des professionnels interviewés, la fabrication de l’environ d’apprentissage est donc centrale dans le sens où elle consiste à agencer la manière dont la machine conçoit le monde : ils savent bien que la pertinence des inférences que cette dernière pourra effectuer dépend étroitement de cette conception.
La conception de l’environnement de traitement
L’environnement de traitement constitue, quant à lui, l’architecture cognitive de la machine proprement dite. Sa conception renvoie à un travail qui est plutôt technique et théorique. En référence aux travaux de Herbert A. Simon (1996), ce travail consiste à élaborer le design du procédé qui permettra à la machine d’inférer des connaissances à partir des données dont elle dispose, c’est-à-dire à régler, à adapter, à fabriquer et/ou à combiner les algorithmes mobilisés (e.g., réseau de neurones, évolution simulée, ou encore, moteur d’inférence). Le rôle de l’implémenteur dans la conception de l’environnement de traitement est généralement de deux ordres. D’une part, l’implémenteur est souvent sollicité par le concepteur pour estimer l’utilité ou non de comprendre les apprentissages effectués par la machine. Si cela n’est pas nécessaire, le concepteur peut concevoir l’environnement de traitement à l’aide d’une ou plusieurs techniques d’apprentissage fonctionnant comme des boîtes noires(6). D’autre part, si le concepteur pense utile de développer une architecture cognitive équipée d’un moteur d’inférence, l’implémenteur est mobilisé pour déterminer et formaliser les règles de déduction que la machine doit pouvoir mettre en action.
Architecture cognitive développée par la société S_01
Architecture cognitive développée par la société S_02
Architecture cognitive développée par la société S_03
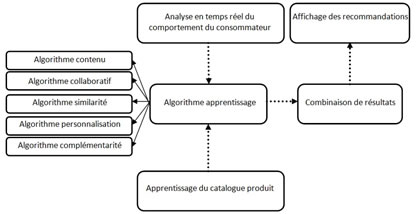
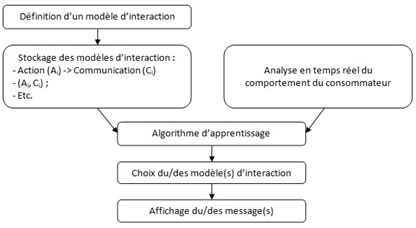
Figure 4 : Exemple d’architectures cognitives appliquées à la gestion de la relation client
Comme l’indique la figure 4, il existe une grande diversité d’architectures cognitives. Celle élaborée par la société S_01 est par exemple composée de cinq algorithmes de recommandation dont la sélection et la combinaison est supervisée par un algorithme d’apprentissage par renforcement. Cet algorithme d’apprentissage permet de décider quel est l’algorithme ou la combinaison d’algorithmes qui est la mieux adaptée en fonction du type de visiteur qui est en train de consulter le site, des évolutions des produits disponibles dans le catalogue de l’e-commerçant et du positionnement des espaces de recommandation à l’intérieur du site.
L’architecture cognitive conçue par la société S_02 est, quant à elle, constituée d’un moteur d’inférence et d’un système d’apprentissage par renforcement. Le moteur d’inférence regroupe plusieurs dizaines de modèles d’interaction qui sont définis avec les implémenteurs de cette technologie. Un de ces modèles est par exemple le suivant : si un consommateur clique x fois sur le même produit au cours des diverses visites du site qu’il a effectuées sur une période de y semaines, alors la machine doit activer la fenêtre pop-up lui présentant un code de promotion. L’algorithme d’apprentissage par renforcement défini alors deux types de modalité d’activation des règles d’inférence. D’une part, il détermine les modalités d’application des modèles d’interaction du moteur d’inférence. Par exemple, dans le cas de la règle que nous venons de mentionner, cet algorithme défini les valeurs de x et de y qui sont économiquement les plus performantes par une série d’essais-erreurs. D’autre part, il cherche à identifier, toujours par le biais de multiples essais-erreurs, à quel point chaque règle stockée dans le moteur d’inférence est plus ou moins efficace en fonction des profils des consommateurs.
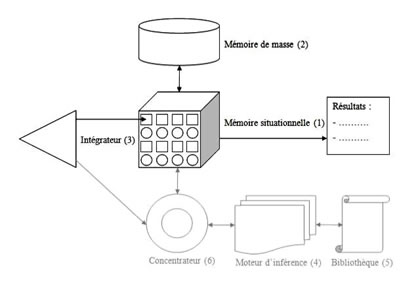
Comme nous l’avons mentionné plus haut, la société S_03 a développé une architecture cognitive différente de celles que nous venons de présenter dans la mesure où celle-ci est dotée d’un module d’apprentissage qui s’apparente à un réseau de neurones profond et d’un module d’inférence. Le fonctionnement de ce système est complexe (cf. Vayre, 2018). Dans les grandes lignes, le module d’apprentissage permet d’induire des situations du type : « les consommateurs qui ont acheté le produit x ont également acheté le produit y ». Ces situations sont ensuite stockées sous forme de règles dans le moteur d’inférence qui peut de ce fait décider de déclencher la recommandation du produit y à chaque fois qu’un consommateur achète le produit x, et inversement. Mais le moteur d’inférence est également souvent utilisé par l’implémenteur pour contrôler l’architecture cognitive de la machine en plaçant en son sein les situations d’activation des stratégies de communication qu’il souhaite que la machine réalise.
La conception de l’environnement politique
L’environnement politique est composé de l’ensemble des critères qui permettent à la machine de contrôler la performance de ses apprentissages. Aussi, même s’il existe des systèmes d’apprentissage qui n’ont pas besoin de ces critères pour fonctionner (cf. les technologies dites non-supervisées ; Cornuéjols & Miclet, 2010), ceux-ci sont généralement associés, au moins en bout de chaîne, à d’autres techniques qui les nécessitent. Les machines ne peuvent en effet souvent rien apprendre d’utile aux yeux de ceux qui les implémentent sans que leurs concepteurs incorporent au sein de leur architecture cognitive les critères qui composent ce que nous appelons l’environnement politique. Et si nous proposons une telle dénomination, c’est parce que le système d’évaluation de la performance que cet environnement constitue a pour principale fonction de donner un sens à l’autonomie cognitive de la machine dans la mesure où il oriente la totalité du travail inférentiel qu’elle effectue.
Par exemple, dans le cas de la société S_03, ces critères de performance sont les indices de préférence que nous avons exposés plus haut, c’est-à-dire les notations que les consommateurs confèrent aux produits du e-commerçant, l’attention qu’ils leur accordent en termes de durée de consultation et l’intérêt qu’ils leur portent en les plaçant ou non dans leurs paniers. Il est alors important de bien comprendre qu’au-delà du fait que la valeur indiciaire de ces critères de préférence soit discutable, les représentations que la machine apprenante de S_03 se construit du monde seraient complètement différentes si son environnement politique ne consistait plus à maximiser les préférences des consommateurs, mais à minimiser leur désorientation. Au regard des entretiens et des observations que nous avons pu effectuer, l’environnement politique est, à l’inverse de l’environnement de traitement, principalement défini par l’implémenteur.

Figure 5 : Extraits de matériau d’enquête
De manière plus générale et en référence au verbatim 4 exposé ci-dessus, la conception d’une technologie d’apprentissage artificiel recouvre un travail de structuration qui consiste à trouver le biais à partir duquel une machine peut se représenter la réalité. Ce biais d’apprentissage résulte de la composition des différents choix qui sont co-élaborés par le concepteur et l’implémenteur pour développer les environnements d’apprentissage, de traitement et politique que nous venons de présenter. Du point de vue du concepteur et de l’implémenteur, c’est ce biais qui est garant de la pertinence des apprentissages que la machine doit réaliser : en orientant les formes de sa socialisation algorithmique, il assure l’utilité socioéconomique de son travail inférentiel et, par voie de conséquence, celle des informations qu’elle communique au sein de l’organisation. C’est précisément en ce sens qu’il faut comprendre qu’en automatisant la communication organisationnelle et sur le plan purement empirique, les technologies d’apprentissage artificiel produisent plus qu’elles ne reproduisent les institutions sociales que représentent les données qui les nourrissent, qu’elles incorporent au sein même des règles d’inférence qu’elles fabriquent et qui composent leur architecture cognitive.
Conclusion
Pour autant, nous avons vu que, sur le plan empirique, les technologies d’apprentissage artificiel recouvrent un travail de conception de trois cadres sociocognitifs qui orientent les formes de la socialisation algorithmique des machines. Dans leur ensemble, ces trois cadres constituent le biais qui permet aux humains de contrôler les formes des apprentissages de la machine et, partant, celles des informations qu’elle fabrique et communique aux entités sociales et techniques qui composent l’organisation. Autrement dit, ce biais d’apprentissage prend la forme concrète d’un ensemble d’opérateurs de traduction qui transforment les régularités que représentent les big data en des informations qui doivent autoriser l’automatisation de la communication organisationnelle. Tout l’enjeu de la conception d’une machine apprenante est alors que cette automatisation apparaisse pertinente du point de vue du concepteur, et surtout, de celui de l’implémenteur. C’est donc en ce sens qu’en référence aux travaux de Yves Jeanneret (2008), les formes de communication automatique qu’instituent les machines apprenantes comportent une dimension logistique, social, mais aussi, poétique : les informations que ces machines produisent et communiquent sont des créations qu’elles réalisent à partir des masses de données qui les nourrissent et en fonction de la façon dont ceux qui les conçoivent et qui les implémentent organisent leurs environnements d’apprentissage, de traitement et politique.
Notes
(1) Nous mobilisons la notion d’apprentissage artificiel plutôt que celle d’apprentissage automatique dans la mesure où, comme le soulignent Antoine Cornuéjols et Laurent Miclet (2010), le qualificatif « automatique » est ambigu. Dans les domaines des sciences cognitives et de l’informatique, il renvoie en effet à des formes de traitement de l’information dit de bas niveau. Or, les technologies d’apprentissage artificiel peuvent réaliser des traitements de haut niveau.
(2) Précisons que, selon Bernard Miège (2007), cette citation est extraite du texte rédigé par le Conseil National Universitaire (CNU) pour définir ce qui est du ressort de la section 71.
(3) C’est par exemple le cas de l’application SwiftKey qui est conçue à partir d’un réseau de neurones artificiels capable d’apprendre les habitudes d’écriture des utilisateurs des smartphones de manière à faciliter la rédaction de texte. Précisons toutefois qu’à l’heure actuelle, il reste toujours difficile de faire fonctionner les réseaux de neurones les plus complexes sur les supports mobiles.
(4) De nombreux travaux en sciences sociales et en psychologie cognitive (cf. Simon, 1996) montrent en effet que la cognition humaine n’est pas seulement composée d’une dimension physique et matérielle, mais aussi d’une dimension symbolique et fonctionnelle.
(5) Car, un peu à la manière dont Bruno Bachimont souligne l’idée que, « plutôt que de considérer la pensée comme une manipulation algorithmique aveugle de symboles, il vaut mieux, au nom du sens, considérer ce que de telles manipulations nous permettent de penser » (2000, p. 317), nous pensons que, plutôt que de considérer que les machines réalisent des formes d’apprentissages analogues à ceux des humains, il vaut mieux considérer qu’elles encapsulent des représentations humaines de ce qu’est l’apprentissage qui leur permettent de faire exister une forme de socialisation bien particulière qui, si elle n’a empiriquement rien à voir avec celle des humains, n’en reste pas moins cruciale pour comprendre les phénomènes de (re)production sociale. Et c’est précisément en ce sens que nous parlons de socialisation algorithmique.
(6) C’est par exemple le cas des réseaux de neurones artificiels, et plus particulièrement des réseaux de neurones dits profonds ou convolutionnels, mais aussi des différentes techniques d’apprentissage par combinaison d’experts que sont les forêts aléatoires, le boosting, ou encore, le bagging (Cornuéjols & Miclet, 2010).
Références bibliographiques
Akrich, Madeleine (1987), « Comment décrire les objets techniques ? », Techniques et culture, n° 9, p. 49-64.
Akrich, Madeleine (1989), « La construction d’un système socio-technique : esquisse pour une anthropologie », Anthropologie et sociétés, vol. 13, n° 2, p. 31-54.
Akrich, Madeleine (2004), « Comment décrire l’interaction entre les techniques et les humains ? » (p. 159-178), in Akrich, Madeleine ; Callon, Michel ; Latour Bruno, Sociologie de la traduction : textes fondamentaux. Paris : Presses des Mines.
Bachimont, Bruno (2000), « L’intelligence artificielle comme écriture dynamique : de la raison graphique à la raison computationnelle » (p. 290-319), in Petitot, Jean ; Fabbri Paolo, Au nom du sens. Autour de l’œuvre d’Umberto Eco, Paris : Grasset.
Bandura, Albert (1986), Social Foundationd of though and action: a social cognitive, Englewood Cliffs: Prentice-Hall.
Bouillon Jean-Luc (2015), « Technologies numériques d’information et de communication et rationalisations organisationnelles : les « compétences numériques » face à la modélisation », Les Enjeux de l’Information et de la Communication, n°16/1, p. 89 à 103, [en ligne]
https://lesenjeux.univ-grenoble-alpes.fr/2015/06-technologies-numeriques-dinformation-et-de-communication-et-rationalisations-organisationnelles-les-competences-numeriques-face-a-la-modelisation
Boullier, Dominique (2016), Sociologie du numérique, Paris : Armand Collin.
Bourdieu, Pierre (1970), La reproduction : éléments d’une théorie du système d’enseignement, Paris : Éditions de minuit.
Bourdieu, Pierre (1994), Raisons pratiques. Sur la théorie de l’action, Paris : Seuil.
Caliskan, Aylin ; Bryson, Joanna J. ; Narayanan, Arvind (2017), « Semantics derived automatically from language corpora contain human-like biases », Science, vol. 356, n° 6334, p. 183-186.
Callon, Michel (1998), The laws of the markets, Oxford: Blackwell.
Cardon, Dominique (2015), A quoi rêvent les algorithmes. Nos vies à l’heure des big data, Paris : Seuil.
Cardon, Dominique ; Casilli, Antonio (2015), Qu’est-ce que le Digital Labor ?, Paris : Édition de l’INA.
Changeux, Jean-Pierre (2006), « Les bases neurales de l’habitus » (p. 143-158), in Fussman, Gérard (dir.), Croyance, raison et déraison, Paris : Odile Jacob.
Cooren, François ; Fairhurst, Gail T. (2009), « Dislocation and stabilization: how to scale up from interactions to organizations » (p. 117-152), in Putnam, Linda L. ; Nicotera, Anne Maydan (dir.), Building theories of organizations: the constitutive role of communication, New York: Routledge.
Cornuéjols, Antoine ; Miclet, Laurent (2010), Apprentissage artificiel : concepts et algorithmes. Paris : Eyrolles.
Crevier, Daniel (1997), À la recherche de l’intelligence artificielle, Paris : Flammarion.
Dagiral, Éric ; Parasie, Sylvain (2017), « La « science des données » à la conquête des mondes sociaux : ce que le « Big Data » doit aux épistémologies locales » (p. 85-104), in Menger Pierre-Michel ; Paye, Simon (dir.), Big data et traçabilité numérique : les sciences sociales face à la quantification massive des individus, Paris : Collège de France.
Denis, Jérôme ; Goëta, Samuel (2017), « La fabrique des données brutes. Le travail en coulisses de l’open data » (p. [en ligne]), in Mabi, Clément ; Plantin, Jean-Christophe ; Monnoyer-Smith, Laurence, Ouvrir,partager, réutiliser. Regards critiques sur les données numériques, Paris : Éditions de la Maison des sciences de l’homme.
Denis, Jérôme ; Pontille, David (2010), « Performativité de l’écrit et travail de maintenance », Réseaux, vol. 5, n° 163, p. 105-130.
Dujarier, Marie-Anne (2008), Le travail du consommateur. De McDo à eBay : comment nous coproduisons ce que nous achetons, Paris : La Découverte.
Forgy, Charles L. (1981), OPS5 user’s manual. tech. rep., Pittsburgh: Computer science department of the Carnegie Mellon University.
Galinon-Mélénec, Béatrice (2011), L’Homme trace. Perspectives anthropologiques des traces contemporaines, Paris : CNRS.
Ganascia, Jean-Gabriel (2017), Intelligence artificielle : vers une domination programmée ?, Paris : Le cavalier bleu.
Giddens, Anthony (1986), The Constitution of Society: outline of the theory of structuration, California: Berkeley.
Hebb, Donald O. (1949), The organization of behavior, New York: Wiley.
Jeanneret, Yves (2008), Penser la trivialité. Volume 1 : la vie triviale des êtres culturels, Paris : Hermès-Lavoisier.
Jeanneret, Yves (2011), « Les harmoniques du Web : espaces d’inscription et mémoire des pratiques », Médiation et Information, n° 32, p. 31-40.
Jeanneret, Yves (2014), « La fabrique de la trace : une entreprise herméneutique » (p. 47-64), in Idjéraoui-Ravez, Linda ; Pélissier, Nicolas (dir.), Quand les traces communiquent… Culture, patrimoine, médiatisation de la mémoire, Paris : Harmattan.
Jézégou, Annie (2014), « L’agentivité humaine : un moteur essentiel pour l’élaboration d’un environnement personnel d’apprentissage », STICEF, n° 21, p. 269-286.
Kohler, Dorothée ; Weisz, Jean-Daniel (2016), « Industrie 4.0 : comment caractériser cette quatrième révolution industrielle et ses enjeux ? », Annales des Mines – Réalités industrielles, n° 4, p. 51-56.
Latour, Bruno (1994), « Une sociologie sans objet ? Remarques sur l’interobjectivité », Sociologie du travail, vol. 36, n° 4, p. 587-607.
Latour, Bruno (1996), « Le « pédofil » de Boa Vista – montage photo-philosophique » (p. 171-225), in Latour, Bruno, Petites leçons de sociologie des sciences, Paris : Seuil.
Laumond, Jean-Paul (2016), « La robotique », Annales des Mines – Réalités industrielles, n° 4, p. 43-46.
Maistre, Christophe (de) (2016), « L’usine cyberphysique : usine connectée, simulée et reconfigurable », Annales des Mines – Réalités industrielles, vol. 4, p. 37-42.
McCulloch, Warren S. ; Pitts, Walter (1943), « A logical calculus of the ideas immanent in nervous activity », The bulletin of mathematical biophysics, vol. 5, n° 4, p. 115-133.
Mead, George H. (2015), Mind, self, and society, Chicago: University of Chicago Press.
Miège, Bernard (2007), « Sur le positionnement de la recherche en histoire des SIC », Questions de communication, n° 12, p. 191-202.
Musso, Pierre (2017), La religion industrielle. Monastère, manufacture, usine. Une généalogie de l’entreprise, Paris : Fayard.
Parsons, Talcott E. (2005), The Social System, New York: Routledge.
Pickering, Andrew (1995), The mangle of practice: time, agency, and science, Chicago: University of Chicago Press.
Rosenblatt, Frank (1958), « The perceptron: a probabilistic model for information storage and organization in the brain », Psychological Review, vol. 65, n° 6, p. 386-408.
Searle, John R. (2004), Mind: a brief introduction, Oxford: Oxford University Press.
Simon, Herbert A. (1996), The sciences of the artificial, Cambridge: MIT Press.
Tiffon, Guillaume (2013), La mise au travail des clients, Paris : Economica.
Tversky, Amos ; Kahneman, Daniel (1974), « Judgment under uncertainty: heuristics and biases », Science, vol. 185, n° 4157, p. 1124-1131.
Vayre, J.-S. (2016), Des machines à produire des futurs économiques : sociologie des intelligences artificielles marchandes à l’ère du big data, Toulouse : Université Toulouse Jean Jaurès.
Vayre, J.-S. (2018), « Machines intelligentes et économie numérique : étude du cas d’un agent artificiel dans le domaine du travail relationnel marchand », Les Cahiers du Numérique, vol. 14, n° 1, p. 83-109.
Auteurs
Jean-Sébastien Vayre
.: Jean-Luc Bouillon est Professeur en Sciences de l’Information et de la Communication à l’Université Rennes 2 et directeur-adjoint du PREFICS (EA 4246). Inscrits dans le champ de la communication organisationnelle, ses travaux portent sur les formes contemporaines de rationalisation des organisations dans leurs aspects informationnels et communicationnels et en relation avec les technologies numériques d’information et de communication (TNIC).